

今年,我们迎来了“第一届” NeurIPS ,也就是改名后的第三十一届 NIPS 会议。NeurIPS(神经信息处理系统进展大会)是神经计算领域的顶级会议,被视为机器学习领域最重要的会议之一。 本次会议共收到投稿 4854 篇,根据官方提供的论文列表,本次会议共收录 1010 篇论文,接收率为 20.8%。 对论文题目进行统计分析,不出意料,占据前三位的实意词语分别为 Learning、Neural、Network(s),均在超过十分一的标题中出现。接下来出现频率较高的词语为 Deep、Optimization、Model(s)、Bayesian、Stochastic、Gradient、Adversarial、Variational、Reinforcement、Data、Generative、Efficient、Inference、Gaussian、Graph、Robust、Linear、Fast 和 Descent。这些词语出现在超过 2% 的题目中。 另外,我们也不难看出,贝叶斯方法、强化学习、GANs、模型的鲁棒性和高效性等是当前研究的热点。  (来源:NeurIPS) 目前,NeurIPS 已经公布了今年的 4 篇最佳论文和时间检验奖。最佳论文中的三篇出自加拿大顶尖大学,加拿大人工智能的实力引人瞩目。另外一篇论文来自 Google AI 。值得一提的是,来自华为实验室的研究者榜上有名。 以下为 4 篇最佳论文的信息: 1、Neural Ordinary Differential Equations 这篇论文来自于加拿大多伦多大学的 Vector Institute。论文中介绍了一类以黑盒 ODE 求解器作为组件的新的深度学习模型,详细介绍了它们的性质、训练细节等。ODE 组建使用一个神经网络对隐藏状态的导数进行参数化,而不再为隐藏层指定一个离散的序列。神经网络的输出由黑盒微分方程求解器计算。利用该组建可以建立用于时间序列、监督学习等的新模型。这些模型的评估自适应性的,可以权衡计算的速度和准确度。 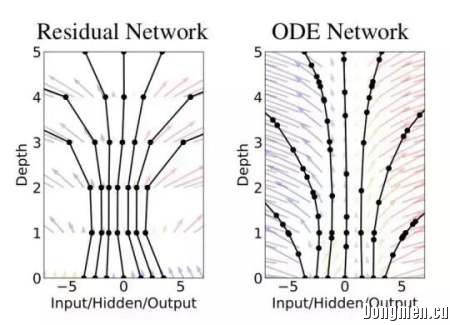 图 | 左:一个残差网络定义了一个只能进行有限变换的离散序列。而 ODE 模型则定义了一个矢量场,其状态可以不断进行转换 2、Nearly tight sample complexity bounds for learning mixtures of Gaussians via sample compression schemes 这篇论文的作者来自加拿大的 McMaster 、Waterloo 等顶尖大学。他们证明了在 d 维空间中,当方差距离小于的情况下,采样对于学习参数为 k 的高斯混合模型是充分且必要的。这进一步精确了之前研究得到的该问题的上界和下界。 3、Optimal Algorithms for Non-Smooth Distributed Optimization in Networks 这篇论文的作者来自华为诺亚方舟实验室、INRIA、微软研究院、华盛顿大学等机构。论文聚焦于包含计算单元的网络的非平滑凸函数的分布优化问题。在两个规律性假设的前提下,作者提出了 MSPD 算法和更简单有效的 DRS 算法。 4、Non-delusional Q-learning and value-iteration 这是一篇与强化学习中 Q-learning 相关的论文,来自 GoogleAI。作者通过函数逼近的方法确定了 Q-learning 和其他动态规划模型中基本误差的基本性来源。当近似模型的框架限制了可表达贪婪策略的类别时,妄想偏差就会产生。为了解决这一问题,作者引入了一种新的一致性策略,并证明使用该策略的基于模型和无模型算法都可以消除妄想偏差,在一般条件下取得最佳结果。最后,作者还提出了几种针对大规模增强学习问题实用的启发式方法,以减轻妄想偏差的影响。 最后,今年的时间检验奖则颁发给了 2007 年的论文 The Tradeoffs of Large Scale Learning 。时间检验奖是一篇论文可以得到的最高赞誉之一,说明一篇论文经受住了时间的考验,对整个领域产生了重大的影响。这篇论文通过一个理论框架,讨论了近似优化对学习算法的影响。计算机计算能力的飞速发展的同时,我们也步入了大数据时代。机器学习、深度学习的特性使得学习理论必须将计算复杂度纳入考量。作者在研究中发现,由于训练数量和训练时间的约束,不同规模学习模型的泛化能力之间存在质的差异。该论文为不同规模模型的细节设计提供了重要的参考。 时间检验奖 特别声明 本文为自媒体、作者等在百度知道日报上传并发布,仅代表作者观点,不代表百度知道日报的观点或立场,知道日报仅提供信息发布平台。合作及供稿请联系zdribao@baidu.com。 来源网址:https://zhidao.baidu.com/daily/view?id=147241 |

GMT-5, 2025-4-12 16:42 , Processed in 0.041088 second(s), 21 queries , Gzip On.
Powered by Discuz! X3.4 © 2001-2013 Comsenz Inc & Style Design











